Query analysis
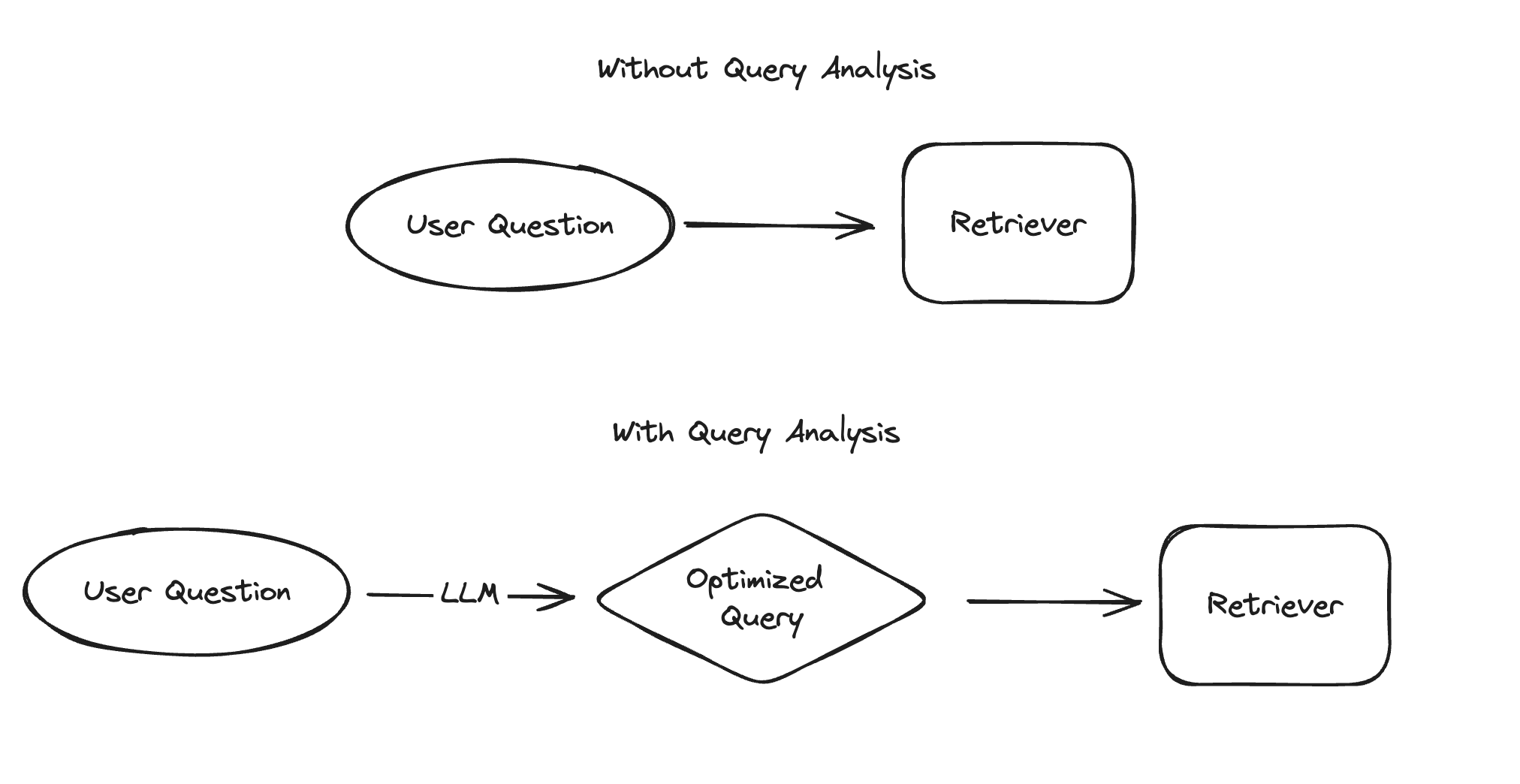
"Search" powers many use cases - including the "retrieval" part of Retrieval Augmented Generation. The simplest way to do this involves passing the user question directly to a retriever. In order to improve performance, you can also "optimize" the query in some way using query analysis. This is traditionally done by rule-based techniques, but with the rise of LLMs it is becoming more popular and more feasible to use an LLM for this. Specifically, this involves passing the raw question (or list of messages) into an LLM and returning one or more optimized queries, which typically contain a string and optionally other structured information.
Problems Solved
Query analysis helps to optimize the search query to send to the retriever. This can be the case when:
- The retriever supports searches and filters against specific fields of the data, and user input could be referring to any of these fields,
- The user input contains multiple distinct questions in it,
- To retrieve relevant information multiple queries are needed,
- Search quality is sensitive to phrasing,
- There are multiple retrievers that could be searched over, and the user input could be reffering to any of them.
Note that different problems will require different solutions. In order to determine what query analysis technique you should use, you will want to understand exactly what is the problem with your current retrieval system. This is best done by looking at failure data points of your current application and identifying common themes. Only once you know what your problems are can you begin to solve them.
Quickstart
Head to the quickstart to see how to use query analysis in a basic end-to-end example. This will cover creating a search engine over the content of LangChain YouTube videos, showing a failure mode that occurs when passing a raw user question to that index, and then an example of how query analysis can help address that issue. The quickstart focuses on query structuring. Below are additional query analysis techniques that may be relevant based on your data and use case
Techniques
There are multiple techniques we support for going from raw question or list of messages into a more optimized query. These include:
- Query decomposition: If a user input contains multiple distinct questions, we can decompose the input into separate queries that will each be executed independently.
- Query expansion: If an index is sensitive to query phrasing, we can generate multiple paraphrased versions of the user question to increase our chances of retrieving a relevant result.
- Hypothetical document embedding (HyDE): If we're working with a similarity search-based index, like a vector store, then searching on raw questions may not work well because their embeddings may not be very similar to those of the relevant documents. Instead it might help to have the model generate a hypothetical relevant document, and then use that to perform similarity search.
- Query routing: If we have multiple indexes and only a subset are useful for any given user input, we can route the input to only retrieve results from the relevant ones.
- Step back prompting: Sometimes search quality and model generations can be tripped up by the specifics of a question. One way to handle this is to first generate a more abstract, "step back" question and to query based on both the original and step back question.
- Query structuring: If our documents have multiple searchable/filterable attributes, we can infer from any raw user question which specific attributes should be searched/filtered over. For example, when a user input specific something about video publication date, that should become a filter on the
publish_dateattribute of each document.
How to
- Add examples to prompt: As our query analysis becomes more complex, adding examples to the prompt can meaningfully improve performance.
- Deal with High Cardinality Categoricals: Many structured queries you will create will involve categorical variables. When there are a lot of potential values there, it can be difficult to do this correctly.
- Construct Filters: This guide covers how to go from a Pydantic model to a filters in the query language specific to the vectorstore you are working with
- Handle Multiple Queries: Some query analysis techniques generate multiple queries. This guide handles how to pass them all to the retriever.
- Handle No Queries: Some query analysis techniques may not generate a query at all. This guide handles how to gracefully handle those situations
- Handle Multiple Retrievers: Some query analysis techniques involve routing between multiple retrievers. This guide covers how to handle that gracefully