Summarize Text
This tutorial demonstrates text summarization using built-in chains and LangGraph.
A previous version of this page showcased the legacy chains StuffDocumentsChain, MapReduceDocumentsChain, and RefineDocumentsChain. See here for information on using those abstractions and a comparison with the methods demonstrated in this tutorial.
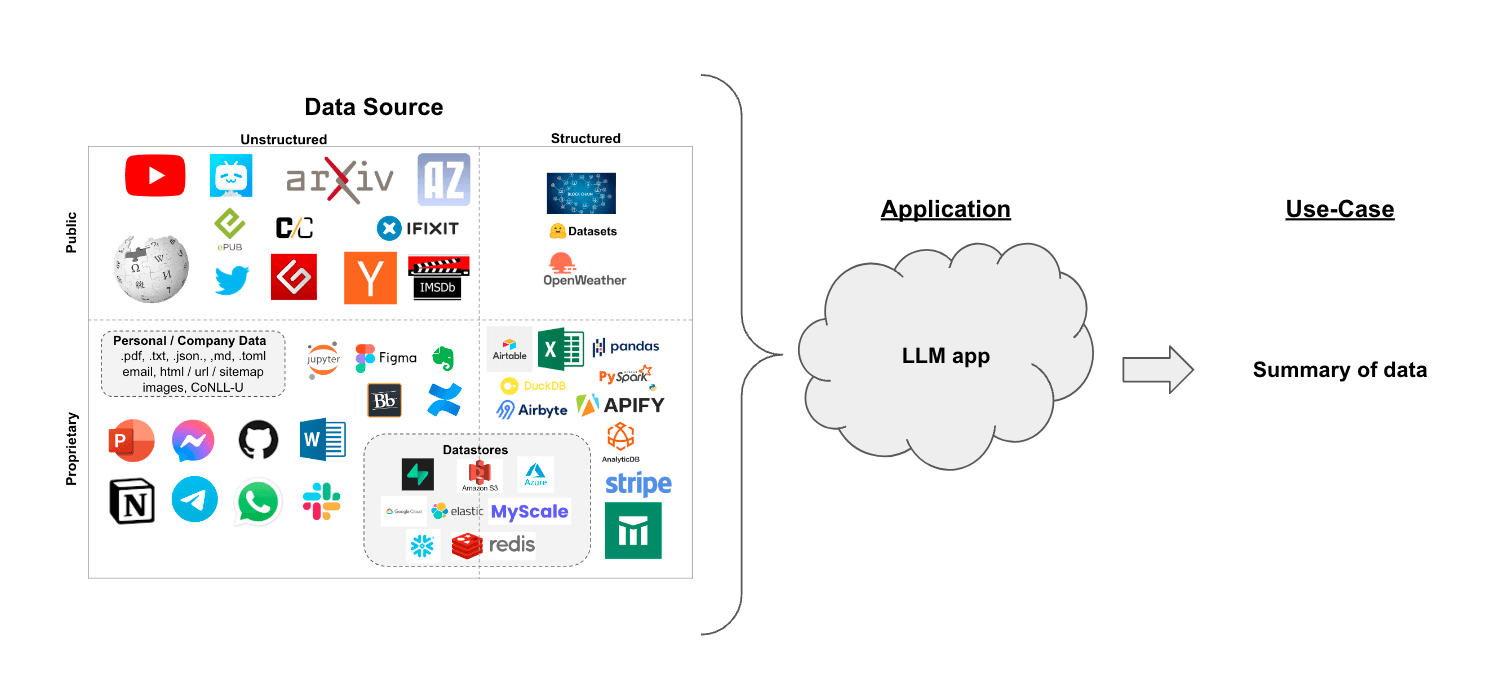
Suppose you have a set of documents (PDFs, Notion pages, customer questions, etc.) and you want to summarize the content.
LLMs are a great tool for this given their proficiency in understanding and synthesizing text.
In the context of retrieval-augmented generation, summarizing text can help distill the information in a large number of retrieved documents to provide context for a LLM.
In this walkthrough we'll go over how to summarize content from multiple documents using LLMs.
Concepts
Concepts we will cover are:
-
Using language models.
-
Using document loaders, specifically the WebBaseLoader to load content from an HTML webpage.
-
Two ways to summarize or otherwise combine documents.
- Stuff, which simply concatenates documents into a prompt;
- Map-reduce, for larger sets of documents. This splits documents into batches, summarizes those, and then summarizes the summaries.
Shorter, targeted guides on these strategies and others, including iterative refinement, can be found in the how-to guides.
Setup
Jupyter Notebook
This guide (and most of the other guides in the documentation) uses Jupyter notebooks and assumes the reader is as well. Jupyter notebooks are perfect for learning how to work with LLM systems because oftentimes things can go wrong (unexpected output, API down, etc) and going through guides in an interactive environment is a great way to better understand them.
This and other tutorials are perhaps most conveniently run in a Jupyter notebook. See here for instructions on how to install.
Installation
To install LangChain run:
- Pip
- Conda
pip install langchain
conda install langchain -c conda-forge
For more details, see our Installation guide.
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
After you sign up at the link above, make sure to set your environment variables to start logging traces:
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
Or, if in a notebook, you can set them with:
import getpass
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
Overview
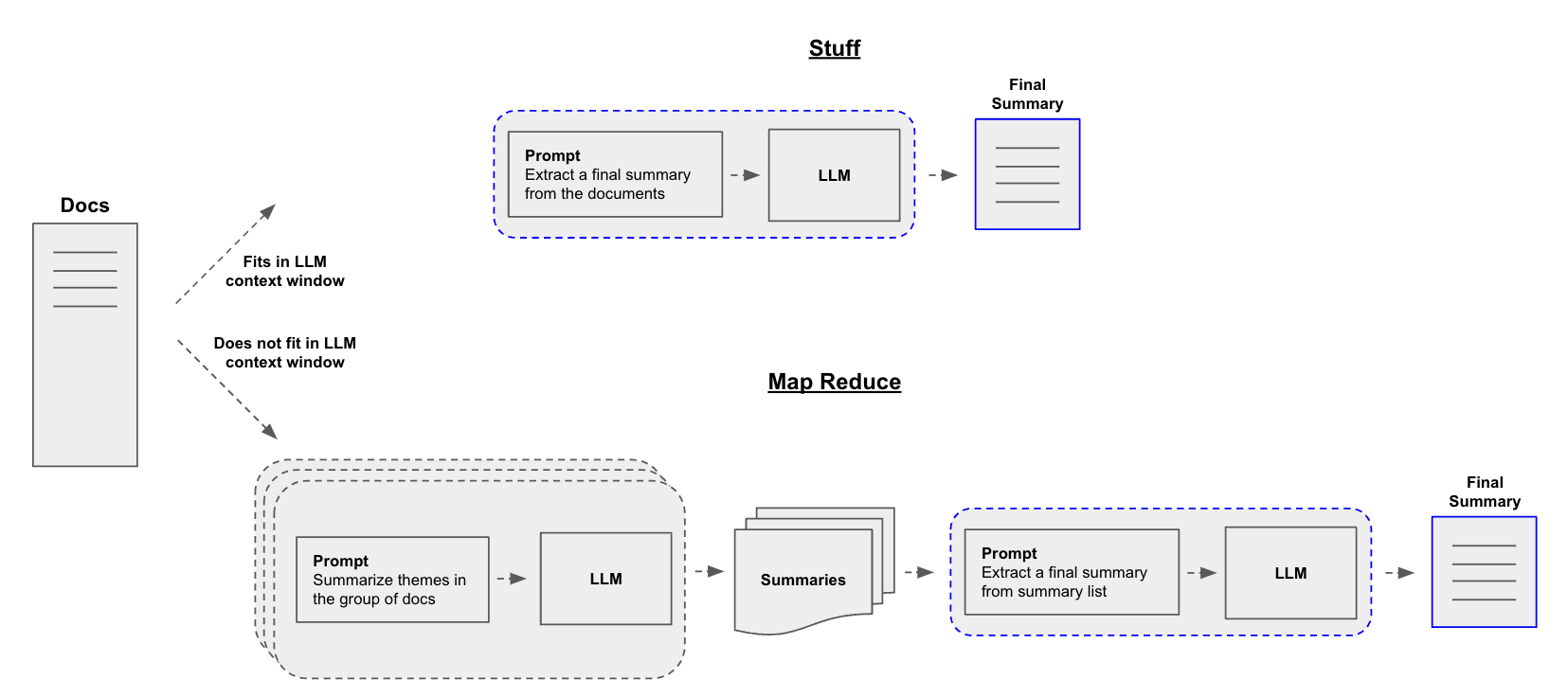
A central question for building a summarizer is how to pass your documents into the LLM's context window. Two common approaches for this are:
-
Stuff: Simply "stuff" all your documents into a single prompt. This is the simplest approach (see here for more on thecreate_stuff_documents_chainconstructor, which is used for this method). -
Map-reduce: Summarize each document on its own in a "map" step and then "reduce" the summaries into a final summary (see here for more on theMapReduceDocumentsChain, which is used for this method).
Note that map-reduce is especially effective when understanding of a sub-document does not rely on preceding context. For example, when summarizing a corpus of many, shorter documents. In other cases, such as summarizing a novel or body of text with an inherent sequence, iterative refinement may be more effective.
Setup
First set environment variables and install packages:
%pip install --upgrade --quiet tiktoken langchain langgraph beautifulsoup4 langchain-community
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
import os
os.environ["LANGSMITH_TRACING"] = "true"
First we load in our documents. We will use WebBaseLoader to load a blog post:
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
Let's next select a LLM:
pip install -qU "langchain[google-genai]"
import getpass
import os
if not os.environ.get("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter API key for Google Gemini: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
Stuff: summarize in a single LLM call
We can use create_stuff_documents_chain, especially if using larger context window models such as:
- 128k token OpenAI
gpt-4o - 200k token Anthropic
claude-3-5-sonnet-latest
The chain will take a list of documents, insert them all into a prompt, and pass that prompt to an LLM:
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
# Define prompt
prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\\n\\n{context}")]
)
# Instantiate chain
chain = create_stuff_documents_chain(llm, prompt)
# Invoke chain
result = chain.invoke({"context": docs})
print(result)
The article "LLM Powered Autonomous Agents" by Lilian Weng discusses the development and capabilities of autonomous agents powered by large language models (LLMs). It outlines a system architecture that includes three main components: Planning, Memory, and Tool Use.
1. **Planning** involves task decomposition, where complex tasks are broken down into manageable subgoals, and self-reflection, allowing agents to learn from past actions to improve future performance. Techniques like Chain of Thought (CoT) and Tree of Thoughts (ToT) are highlighted for enhancing reasoning and planning.
2. **Memory** is categorized into short-term and long-term memory, with mechanisms for fast retrieval using Maximum Inner Product Search (MIPS) algorithms. This allows agents to retain and recall information effectively.
3. **Tool Use** enables agents to interact with external APIs and tools, enhancing their capabilities beyond the limitations of their training data. Examples include MRKL systems and frameworks like HuggingGPT, which facilitate task planning and execution.
The article also addresses challenges such as finite context length, difficulties in long-term planning, and the reliability of natural language interfaces. It concludes with case studies demonstrating the practical applications of these concepts in scientific discovery and interactive simulations. Overall, the article emphasizes the potential of LLMs as powerful problem solvers in autonomous agent systems.
Streaming
Note that we can also stream the result token-by-token:
for token in chain.stream({"context": docs}):
print(token, end="|")
|The| article| "|LL|M| Powered| Autonomous| Agents|"| by| Lil|ian| W|eng| discusses| the| development| and| capabilities| of| autonomous| agents| powered| by| large| language| models| (|LL|Ms|).| It| outlines| a| system| architecture| that| includes| three| main| components|:| Planning|,| Memory|,| and| Tool| Use|.|
|1|.| **|Planning|**| involves| task| decomposition|,| where| complex| tasks| are| broken| down| into| manageable| sub|go|als|,| and| self|-ref|lection|,| allowing| agents| to| learn| from| past| actions| to| improve| future| performance|.| Techniques| like| Chain| of| Thought| (|Co|T|)| and| Tree| of| Thoughts| (|To|T|)| are| highlighted| for| enhancing| reasoning| and| planning|.
|2|.| **|Memory|**| is| categorized| into| short|-term| and| long|-term| memory|,| with| mechanisms| for| fast| retrieval| using| Maximum| Inner| Product| Search| (|M|IPS|)| algorithms|.| This| allows| agents| to| retain| and| recall| information| effectively|.
|3|.| **|Tool| Use|**| emphasizes| the| integration| of| external| APIs| and| tools| to| extend| the| capabilities| of| L|LM|s|,| enabling| them| to| perform| tasks| beyond| their| inherent| limitations|.| Examples| include| MR|KL| systems| and| frameworks| like| Hug|ging|GPT|,| which| facilitate| task| planning| and| execution|.
|The| article| also| addresses| challenges| such| as| finite| context| length|,| difficulties| in| long|-term| planning|,| and| the| reliability| of| natural| language| interfaces|.| It| concludes| with| case| studies| demonstrating| the| practical| applications| of| L|LM|-powered| agents| in| scientific| discovery| and| interactive| simulations|.| Overall|,| the| piece| illustrates| the| potential| of| L|LM|s| as| general| problem| sol|vers| and| their| evolving| role| in| autonomous| systems|.||
Go deeper
- You can easily customize the prompt.
- You can easily try different LLMs, (e.g., Claude) via the
llmparameter.
Map-Reduce: summarize long texts via parallelization
Let's unpack the map reduce approach. For this, we'll first map each document to an individual summary using an LLM. Then we'll reduce or consolidate those summaries into a single global summary.
Note that the map step is typically parallelized over the input documents.
LangGraph, built on top of langchain-core, supports map-reduce workflows and is well-suited to this problem:
- LangGraph allows for individual steps (such as successive summarizations) to be streamed, allowing for greater control of execution;
- LangGraph's checkpointing supports error recovery, extending with human-in-the-loop workflows, and easier incorporation into conversational applications.
- The LangGraph implementation is straightforward to modify and extend, as we will see below.
Map
Let's first define the prompt associated with the map step. We can use the same summarization prompt as in the stuff approach, above:
from langchain_core.prompts import ChatPromptTemplate
map_prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\\n\\n{context}")]
)
We can also use the Prompt Hub to store and fetch prompts.
This will work with your LangSmith API key.
For example, see the map prompt here.
from langchain import hub
map_prompt = hub.pull("rlm/map-prompt")
Reduce
We also define a prompt that takes the document mapping results and reduces them into a single output.
# Also available via the hub: `hub.pull("rlm/reduce-prompt")`
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""
reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
Orchestration via LangGraph
Below we implement a simple application that maps the summarization step on a list of documents, then reduces them using the above prompts.
Map-reduce flows are particularly useful when texts are long compared to the context window of a LLM. For long texts, we need a mechanism that ensures that the context to be summarized in the reduce step does not exceed a model's context window size. Here we implement a recursive "collapsing" of the summaries: the inputs are partitioned based on a token limit, and summaries are generated of the partitions. This step is repeated until the total length of the summaries is within a desired limit, allowing for the summarization of arbitrary-length text.
First we chunk the blog post into smaller "sub documents" to be mapped:
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
print(f"Generated {len(split_docs)} documents.")
Created a chunk of size 1003, which is longer than the specified 1000
``````output
Generated 14 documents.
Next, we define our graph. Note that we define an artificially low maximum token length of 1,000 tokens to illustrate the "collapsing" step.
import operator
from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import (
acollapse_docs,
split_list_of_docs,
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraph
token_max = 1000
def length_function(documents: List[Document]) -> int:
"""Get number of tokens for input contents."""
return sum(llm.get_num_tokens(doc.page_content) for doc in documents)
# This will be the overall state of the main graph.
# It will contain the input document contents, corresponding
# summaries, and a final summary.
class OverallState(TypedDict):
# Notice here we use the operator.add
# This is because we want combine all the summaries we generate
# from individual nodes back into one list - this is essentially
# the "reduce" part
contents: List[str]
summaries: Annotated[list, operator.add]
collapsed_summaries: List[Document]
final_summary: str
# This will be the state of the node that we will "map" all
# documents to in order to generate summaries
class SummaryState(TypedDict):
content: str
# Here we generate a summary, given a document
async def generate_summary(state: SummaryState):
prompt = map_prompt.invoke(state["content"])
response = await llm.ainvoke(prompt)
return {"summaries": [response.content]}
# Here we define the logic to map out over the documents
# We will use this an edge in the graph
def map_summaries(state: OverallState):
# We will return a list of `Send` objects
# Each `Send` object consists of the name of a node in the graph
# as well as the state to send to that node
return [
Send("generate_summary", {"content": content}) for content in state["contents"]
]
def collect_summaries(state: OverallState):
return {
"collapsed_summaries": [Document(summary) for summary in state["summaries"]]
}
async def _reduce(input: dict) -> str:
prompt = reduce_prompt.invoke(input)
response = await llm.ainvoke(prompt)
return response.content
# Add node to collapse summaries
async def collapse_summaries(state: OverallState):
doc_lists = split_list_of_docs(
state["collapsed_summaries"], length_function, token_max
)
results = []
for doc_list in doc_lists:
results.append(await acollapse_docs(doc_list, _reduce))
return {"collapsed_summaries": results}
# This represents a conditional edge in the graph that determines
# if we should collapse the summaries or not
def should_collapse(
state: OverallState,
) -> Literal["collapse_summaries", "generate_final_summary"]:
num_tokens = length_function(state["collapsed_summaries"])
if num_tokens > token_max:
return "collapse_summaries"
else:
return "generate_final_summary"
# Here we will generate the final summary
async def generate_final_summary(state: OverallState):
response = await _reduce(state["collapsed_summaries"])
return {"final_summary": response}
# Construct the graph
# Nodes:
graph = StateGraph(OverallState)
graph.add_node("generate_summary", generate_summary) # same as before
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)
# Edges:
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
graph.add_edge("generate_final_summary", END)
app = graph.compile()
LangGraph allows the graph structure to be plotted to help visualize its function:
from IPython.display import Image
Image(app.get_graph().draw_mermaid_png())

When running the application, we can stream the graph to observe its sequence of steps. Below, we will simply print out the name of the step.
Note that because we have a loop in the graph, it can be helpful to specify a recursion_limit on its execution. This will raise a specific error when the specified limit is exceeded.
async for step in app.astream(
{"contents": [doc.page_content for doc in split_docs]},
{"recursion_limit": 10},
):
print(list(step.keys()))
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['collect_summaries']
['collapse_summaries']
['collapse_summaries']
['generate_final_summary']
print(step)
{'generate_final_summary': {'final_summary': 'The consolidated summary of the main themes from the provided documents is as follows:\n\n1. **Integration of Large Language Models (LLMs) in Autonomous Agents**: The documents explore the evolving role of LLMs in autonomous systems, emphasizing their enhanced reasoning and acting capabilities through methodologies that incorporate structured planning, memory systems, and tool use.\n\n2. **Core Components of Autonomous Agents**:\n - **Planning**: Techniques like task decomposition (e.g., Chain of Thought) and external classical planners are utilized to facilitate long-term planning by breaking down complex tasks.\n - **Memory**: The memory system is divided into short-term (in-context learning) and long-term memory, with parallels drawn between human memory and machine learning to improve agent performance.\n - **Tool Use**: Agents utilize external APIs and algorithms to enhance problem-solving abilities, exemplified by frameworks like HuggingGPT that manage task workflows.\n\n3. **Neuro-Symbolic Architectures**: The integration of MRKL (Modular Reasoning, Knowledge, and Language) systems combines neural and symbolic expert modules with LLMs, addressing challenges in tasks such as verbal math problem-solving.\n\n4. **Specialized Applications**: Case studies, such as ChemCrow and projects in anticancer drug discovery, demonstrate the advantages of LLMs augmented with expert tools in specialized domains.\n\n5. **Challenges and Limitations**: The documents highlight challenges such as hallucination in model outputs and the finite context length of LLMs, which affects their ability to incorporate historical information and perform self-reflection. Techniques like Chain of Hindsight and Algorithm Distillation are discussed to enhance model performance through iterative learning.\n\n6. **Structured Software Development**: A systematic approach to creating Python software projects is emphasized, focusing on defining core components, managing dependencies, and adhering to best practices for documentation.\n\nOverall, the integration of structured planning, memory systems, and advanced tool use aims to enhance the capabilities of LLM-powered autonomous agents while addressing the challenges and limitations these technologies face in real-world applications.'}}
In the corresponding LangSmith trace we can see the individual LLM calls, grouped under their respective nodes.
Go deeper
Customization
- As shown above, you can customize the LLMs and prompts for map and reduce stages.
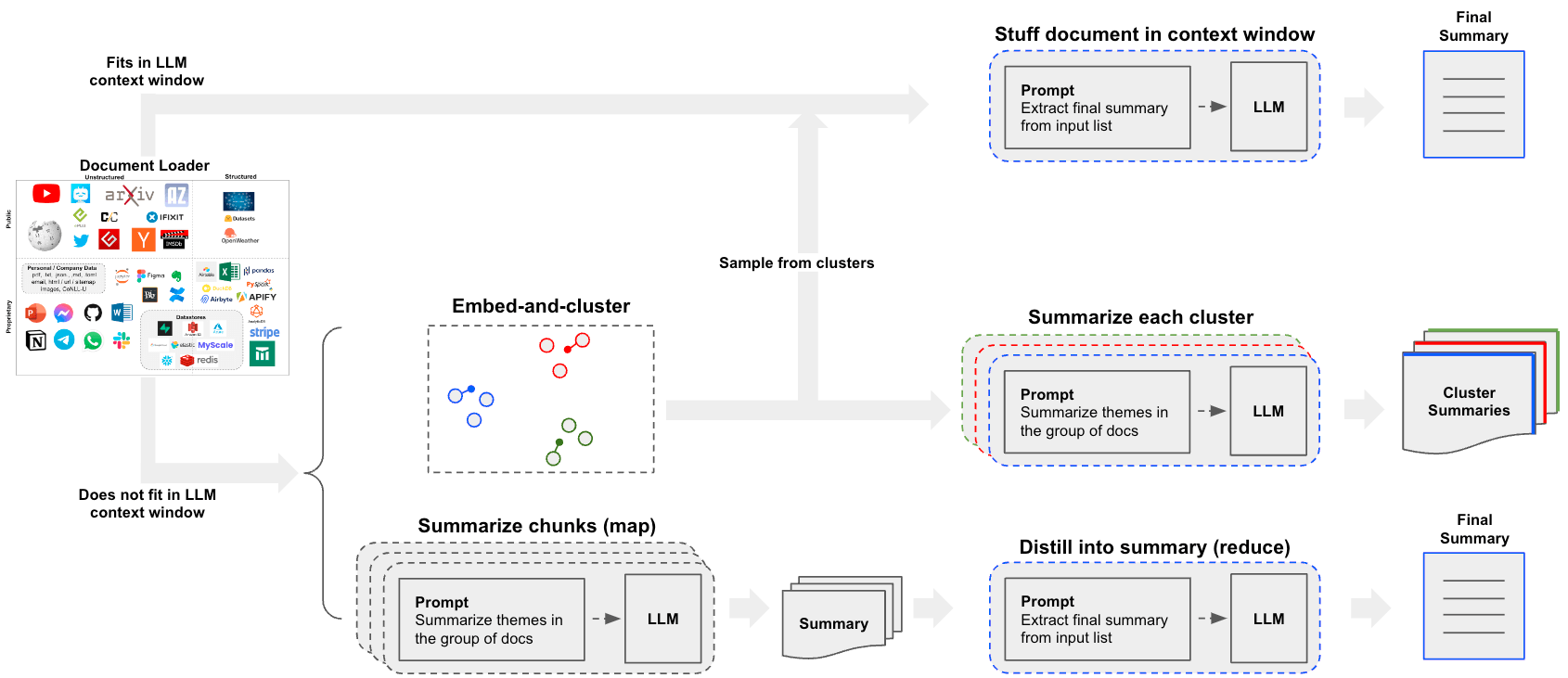
Real-world use-case
- See this blog post case-study on analyzing user interactions (questions about LangChain documentation)!
- The blog post and associated repo also introduce clustering as a means of summarization.
- This opens up another path beyond the
stufformap-reduceapproaches that is worth considering.
Next steps
We encourage you to check out the how-to guides for more detail on:
- Other summarization strategies, such as iterative refinement
- Built-in document loaders and text-splitters
- Integrating various combine-document chains into a RAG application
- Incorporating retrieval into a chatbot
and other concepts.